Descriptive Statistical Methods in Code
Statistics can be mighty useful, and a little programming helps it getting even better. I often find that I through code can grasp the fundamental function behind how things work, and I have tried to apply this to statistics as well. In this case to descriptive statistics.
Join me in this short attempt to let statistics unconceal itself.
Getting ready: Extremistan and Mediocristan
This little text is looking closer on some of the descriptive methods of statistics, and to do that I want to use proper dataset. I have collected two data-sets following two different paradigms. The first dataset follows the rule of normal distribution/bell curve, derives from the physical world and is little susceptible to what Nassim Nicholas Taleb has identifies as the domain of Black Swans. In Mediocristan values seldom deviates, and when they do it’s not extremely.
On the other hand, our second dataset is from the social world where values does not conform to the bell curve, and where single values may change the whole dataset. In the domain of Extremistan values found includes many from the socio-cultural domains including number of cultural items sold, wealth, and number of Twitter followers.
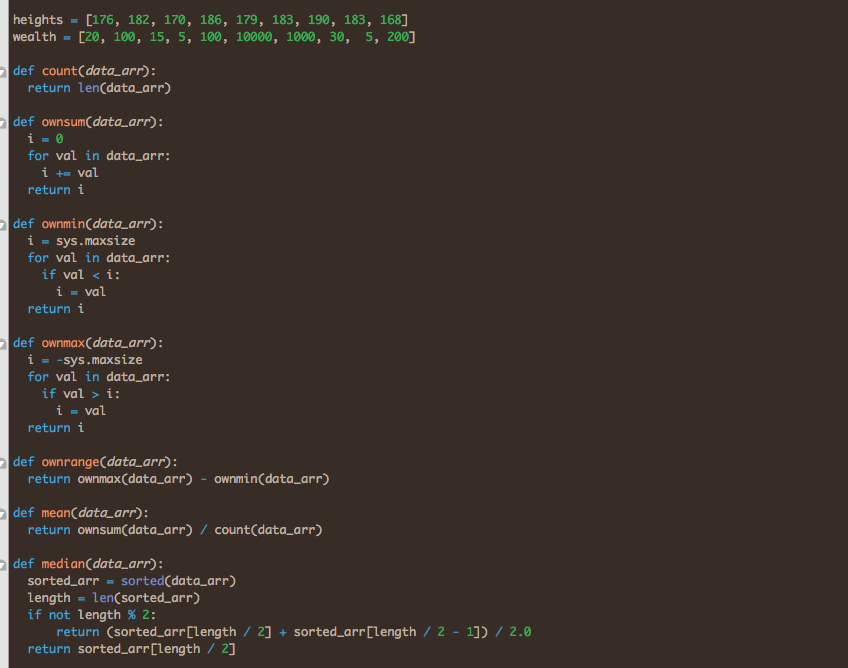
Hights of 10 people = 176, 182, 170, 186, 179, 183, 190, 183, 168, 180
Wealth of 10 people (imagined denomination) = 20, 100, 15, 5, 100, 10000, 1000, 30, 5, 200
To compute upon our values, we will save them into arrays.
[sourcecode language=”python”]
heights = [176, 182, 170, 186, 179, 183, 190, 183, 168, 180]
wealth = [20, 100, 15, 5, 100, 10000, 1000, 30, 5, 200]
[/sourcecode]
The count
This method is as simple as it gets. The count does not look at any of the numeric value stored, it just count the number of occurrences. In Python we have the comprehensive method len() to which we can pass the array and get returned the length.
[sourcecode language=”python”]
def count(data_arr):
return len(data_arr)
[/sourcecode]
The sum
To find the sum of the elements, we need to look in on the values and add these together. This is done by iterating through all the elements and add the value of all the elements to a single variable which we then return. Python has already a sum method implemented which does exactly what we need, but instead of using this we make our own: ownsum
[sourcecode language=”python”]
def ownsum(data_arr):
i = 0
for val in data_arr:
i += val
return i
[/sourcecode]
The min
All the values we have in both our arrays are comparable, the height is measured in centimetres and the wealth in a denomination. A higher number refers to more, and a lower number to less of that measure. The min, or minimum, finds the smallest value and returns this. To do this we need to start with the first number and always retain the smallest value we iterate over. In the implementation below the start value is set to the maximum value available to the system. To get this value will need to import the sys (system) library. Python already have a min method, so we implement our own: ownmin.
[sourcecode language=”python”]
import sys
def ownmin(data_arr):
i = sys.maxsize
for val in data_arr:
if val < i:
i = val
return i
[/sourcecode]
The max
The max method is somewhat a reversed min method. It looks at all the values and find the largest number. To get here we need to always retain the largest number as we iterate over the array. We start with the smallest possible value and then iterate. The max function is already implemented in Python, so we write our own: ownmax
[sourcecode language=”python”]
def ownmax(data_arr):
i = -sys.maxsize
for val in data_arr:
if val > i:
i = val
return i
[/sourcecode]
The range
The range is the numerical difference between the smallest and the largest value. This can give us a quick indication on the speadth of data. The range is fairly easy to find using subtraction. If we subtract the min from the max we are left with the range. We could write a whole function first performing the calculations for min and max and then do the subtraction, but since we already have implemented our own ownmin and ownmax methods, why not take advantage of our work already done. Python already has a function named range, so to avoid namespace problems let us implement the method ownrange
[sourcecode language=”python”]
def ownrange(data_arr):
return ownmax(data_arr) – ownmin(data_arr)
[/sourcecode]
The mean/arithmetic average
The mean, or the arithmetic average tells us something about the central tendency. The mode and the median average does so as well, but where the mode looks at occurrences and median look at the central element in an order list, the arithmetic average takes the sum of all elements and divide on the count. This is the most common way of finding the central tendency, but it is also prone to misunderstand large deviations in the dataset.
[sourcecode language=”python”]
def mean(data_arr):
return ownsum(data_arr) / count(data_arr)
[/sourcecode]
The median average
For the median average the values of each element is less importance, the paramount here is the position at where the elements can be found in relation to each other. The median is basically the middle element of an sorted array. If the array has an even number of elements the median is the aritmetic average of the two middle values. In the implementation of the method we first sort the array, then we get the length. If the length of the array is divisible by two (even number of elements) we return the average of the two middle values, if not we return the value of the middle element.
[sourcecode language=”python”]
def median(data_arr):
sorted_arr = sorted(data_arr)
length = len(sorted_arr)
if not length % 2:
return (sorted_arr[length / 2] + sorted_arr[length / 2 – 1]) / 2.0
return sorted_arr[length / 2]
[/sourcecode]
The mode average
The mode average is the most frequent value of the dataset. In our case this may not be representative, but if you have large datasets with many datapoints it makes more sense. The mode can be used trying to identify the distribution of the data. Often we have a mental anchor of the dataset having a unimodal distribution with a central peak with the most frequent occurrences of values in the centre and descending frequencies as we move away from the centre in both directions (e.g. the Empirical rule and bell curves), but datasets can also be bimodal with two centres towards each end of the spectre and few frequencies towards the centre. In a large dataset, the mode can help us spot these tendencies as it allows for more mode averages. For example a dataset with a range from 10 to 30 may have a unimodal distribution with a mode at 20, but also have a bimodal distribution with a mode at 15 and 25, this would be hard to spot for both the median and arithmetic averages.
To find the mode we need to create a dictionary. In this dictionary we create a key for each of the distinct values and a frequency of these. Once we have the dictionary, we need to iterate this to find the most frequent values. A mode can consist of more values, so we need to check the value of all the dictionary items against the max number of frequencies and return the element, or all elements that has this number of occurrences. Be aware that if none of the distinct values have more than one occurrences, all occurrences are returned.
[sourcecode language=”python”]
def mode(data_arr):
frequencies = {}
for i in data_arr:
frequencies[i] = frequencies.get(i, 0) + 1
max_freq = ownmax(frequencies.itervalues())
modes = [k for k, v in frequencies.iteritems() if v == max_freq]
return modes
[/sourcecode]
The variance of a population
The variance is used for finding the spread in the dataset. In the average methods above we found the central tendency of the dataset, and now we need to see how much the values of the dataset conforms to this number. For these values you can find whether you dataset is more extreme or mediocre (these are not binary groups, but gravitating centres). Once presented with an average from a dataset, a good follow up question is to ask for the standard deviation (next method). The variance is the sum of each values difference from the mean. To implement this method we first find the arithmetic mean for the dataset, and then iterate over all values comparing them to the average. Since the difference can be both higher and lower than the average, and we want to operate with positive numbers we square each value.
[sourcecode language=”python”]
def variance(data_arr):
variance = 0
average = mean(data_arr)
for i in data_arr:
variance += (average – i) **2
return variance / count(data_arr)
[/sourcecode]
The standard deviation
From the variance the way to the standard deviation is fairly simple. The standard deviation is the square root of the variance. This has the same measure as the average and is easier to compare. Here we take advantage of our last method and run a square root method on this to get the standard deviation. The sqrt method needs to be imported from the maths library. Be aware that standard deviation and variance is treated differently whether working with a sample or with a population. The differences is outside the scope of this article.
[sourcecode language=”python”]
import math
def stddev(data_arr):
return math.sqrt(variance(data_arr))
[/sourcecode]
The final code
We have now implemented some of the basic descriptive methods in statistics. The whole project can be found below. To run some of the functions. Call them by their method name and pass in an array. Two 10 elements long arrays can be found in the script, but the methods are implemented in such a way that you can pass with an array of any length.
[sourcecode language=”python”]
import sys
import math
heights = [176, 182, 170, 186, 179, 183, 190, 183, 168]
wealth = [20, 100, 15, 5, 100, 10000, 1000, 30, 5, 200]
def count(data_arr):
return len(data_arr)
def ownsum(data_arr):
i = 0
for val in data_arr:
i += val
return i
def ownmin(data_arr):
i = sys.maxsize
for val in data_arr:
if val < i: i = val return i def ownmax(data_arr): i = -sys.maxsize for val in data_arr: if val > i:
i = val
return i
def ownrange(data_arr):
return ownmax(data_arr) – ownmin(data_arr)
def mean(data_arr):
return ownsum(data_arr) / count(data_arr)
def median(data_arr):
sorted_arr = sorted(data_arr)
length = len(sorted_arr)
if not length % 2:
return (sorted_arr[length / 2] + sorted_arr[length / 2 – 1]) / 2.0
return sorted_arr[length / 2]
def mode(data_arr):
frequencies = {}
for i in data_arr:
frequencies[i] = frequencies.get(i, 0) + 1
max_freq = ownmax(frequencies.itervalues())
modes = [k for k, v in frequencies.iteritems() if v == max_freq]
return modes
def variance(data_arr):
variance = 0
average = mean(data_arr)
for i in data_arr:
variance += (average – i) **2
return variance / count(data_arr)
def stddev(data_arr):
return math.sqrt(variance(data_arr))
[/sourcecode]